KPNet: Towards Minimal Face Detector
2020, May 06
Paper: Zhu et al., “Seeing Small Faces from Robust Anchor’s Perspective.”
问题
- 作者认为对于一般的人脸, 小而浅的网络的特征就足够区分人脸和背景, 问题在于
- 人脸框的定义存在模糊性
- Anchor 和 感受野的确定比较困难
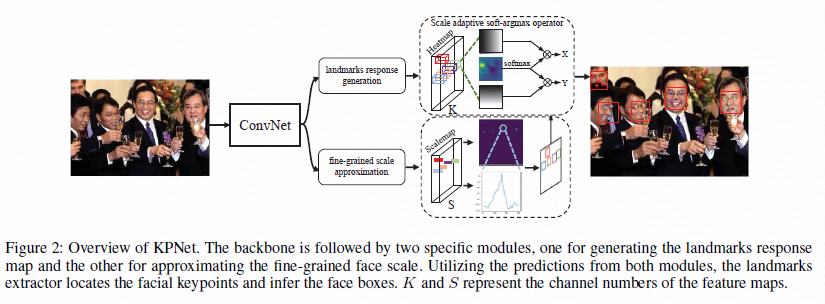
方法
- 采用自下而上的方法: 抛弃人脸框, 转而直接预测人脸五官(关键点)的位置
- 抛弃 Anchor 方法, 用尺度图 (ScaleMap) 预测人脸的尺度
实现
- 细腻度的尺度估计: 可以理解为预测 N 张响应图, 每一张响应图代表某个尺度的 bin. 作者把人脸大小从 \(2^5\) 到 \(2^11\)分成了60个 bin , 也就是预测60个通道的 ScaleMap.
- 如果某个人脸的尺度落在某张响应图所在范围上, 那么这个人脸中心位置的响应值则为 1, 但是这样离散的响应图, 不好训. 作者将响应图转变为高斯形态的响应图. 计算如下
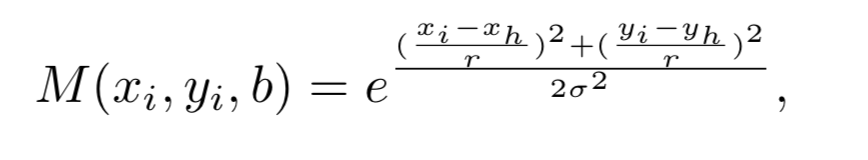
其中 \((x_h, y_h)\) 是人脸中心在特征图的位置(经过stride换算), 半径 \(r = \lfloor \frac{b}{10} \rfloor\). 简单理解就是人脸越大, 相应点的半径越大. 这一点也是挺合理的. (直接采用人脸真实大小为半径, 会不会更好呢?) - 响应图的训练采用 BCE loss
- soft-argmax: 一般响应图得出坐标的方式是去相应最大位置的 x, y 坐标, 即 argmax 操作, 不可导. 作者就用积分的方式, 实际上是一个方形核的核密度估计求取坐标, 这个方法其实很常见, 并不是本文第一次提出.
- 坐标的loss 采用二范距离
结果
- 在 FDDB, AFW, MALF 上均取得较好的结果
点评
- 训练集不明确, 文中只提到 AFLW 的训练集, 不知道有没有额外的数据集加入训练
- 为什么要采用 soft-argmax 操作训练关键点热度图, 直接用热度图监督可以吗? 差异有多少? soft-argmax 带来多少好处?
- 该方法对于人脸遮挡问题还有效吗? 在遮挡情况下人脸点已经看不见了.
- 在 WIDER FACE 上的表现如何?
- 文章指出了 anchor 的弊端, scalemap 实际上是一个尺度分布非常密集的 anchor ?!