FaceScape: a Large-scale High Quality 3D Face Dataset and Detailed Riggable 3D Face Prediction
传统机器学习算法靠脑力, 深度学习时代靠算例, 数据时代靠财力. – 佚名
Paper: https://arxiv.org/abs/2003.13989
Code: https://github.com/zhuhao-nju/facescape
人脸三维重建的目的可以概括为两方面, 一方面对于人脸进行高精度的重建, 包括身份, 姿态, 表情, 纹理, 细节等等; 另一方面在
重建的基础上进行迁移, 生成等应用. 这篇论文是一篇非常完整的, 从建模到应用都有涉及的文章. 其中采集和建立数据集, 和构建
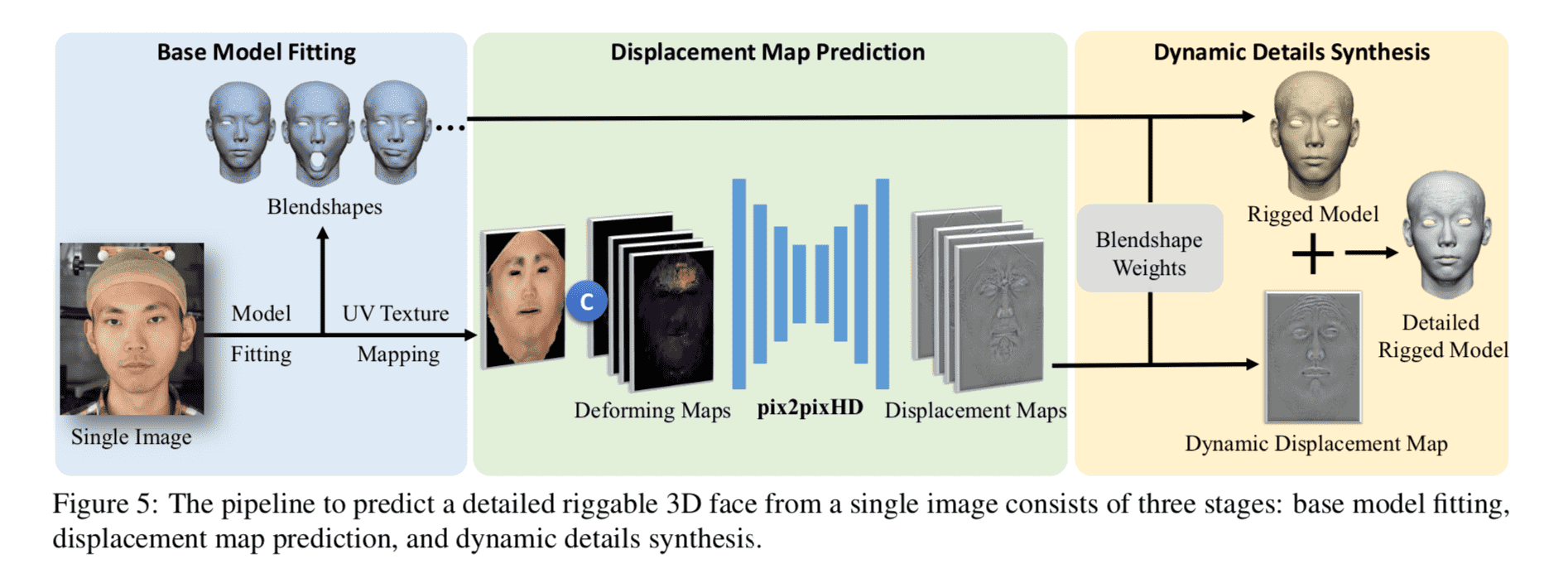
人脸模型(采用双线性模型)与之前的工作相比没有特别之处. 较为创新和新颖的地方在于, 对人脸不同的表情下的动态偏移(Dynamic Displacement)
进行建模, 使得模型在传统3DMM的基础上增加了另个自由度或者说是基, 是对传统3DMM的重要补充. 正是由于动态偏移类似于身份, 表情这些基, 使得细节是可以控制的(riggable). 动态偏移不仅提升了重建的精度, 而且在迁移生成中,保证了细节, 使得生成结果更逼真.
FaceScape 数据集
虽然数据集和建模没有特别之处, 但是作者表示要开源(非商业用途), 可谓业界良心, 让我们一起期待 😄!
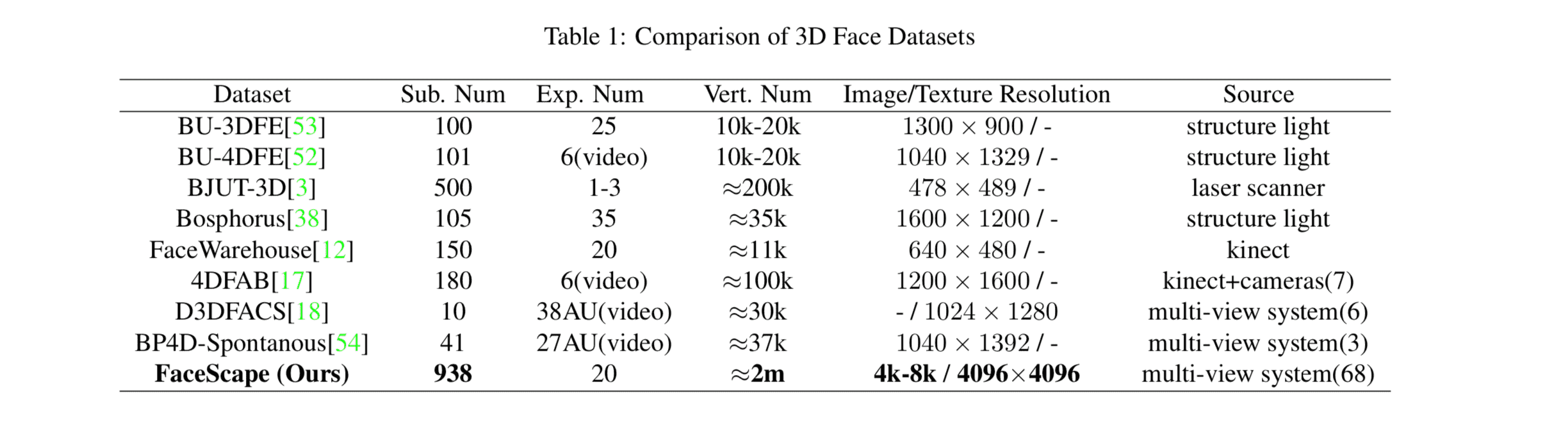
三维数据生成采用的多视图重建的方案. 采集了928个不同的人, 总共18,760个模型, 模型的顶点数达到200万个. 这个规模在业界是很大的. 看作者和业界的对比就知道了. 见 Table1.
Dynamic Displacement
建模和3D模型拟合与以往的工作差异不大, 在此不再赘述. 我们着重讲下作者是如何对于动态偏移进行建模的. 个人认为这个动态偏移的建模分为两个方面:
- 偏移图动态生成, 对应文章4.2节
- 偏移图动态加权组合, 对应文章4.3节
预测偏移基
Displacement Map在我看来是3DMM拟合之后与真实三维模型之间的差距, 也就是传统3DMM无法表达的那部分. 文章认为, 这部分余量包括两个部分, 一个是人脸本征(如痔, 毛孔等), 这些信息包含在纹理, 另一部分与表情相关 ,即不同的表情表现出了不同的偏移差异. 所以作者就训了一个网络来预测不同的纹理,和不同表情的运行分布图(Deforming Maps)下的偏移基. 作者标题叫做”Displacement Map Prediction”, 我认为应该改为 “Displacement Base Map” 更为贴切😜. 这么干, 我认为有两点好处: 1) 充分利用了深度学习对于信息的编码; 2) 输入当前人脸信息, 使得预测出的偏移基因”人”而异, 因”表情”而异!
加权组合
文章4.2节预测了20个基本表情的偏移基. 但是blendshape有51个. 这才有4.3节这么多的麻烦事儿.
首先我们想确定最终的偏移图, 它是所有偏移基的逐像素加权组合
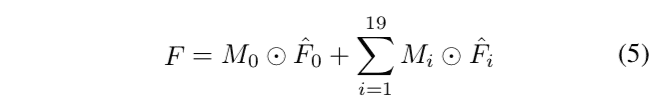
其中\(M_j\)的权重由当前人脸blendshape和目标人脸blendshape的权重, 以及不同表情下和无表情时的顶点偏移共同决定. 即:
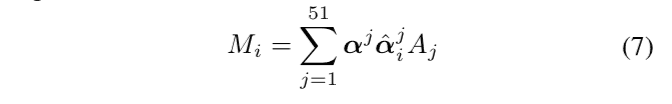
其中\(\alpha\)为目标表情的系数, \(\hat{\alpha}\)为当前表情的blendshape系数. \(A_j\)是不同表情下的顶点距离, 即:
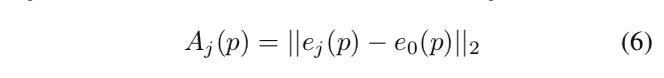
当然最后还得计算无表情时的权重: \(M_0=max(0,1 - \sum_{i=1}^{19}{M_i}\).
参考资料
-
“High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs.” https://tcwang0509.github.io/pix2pixHD/ (accessed Apr. 06, 2020). ↩
-
“paGAN: real-time avatars using dynamic textures: ACM Transactions on Graphics: Vol 37, No 6.” https://dl.acm.org/doi/abs/10.1145/3272127.3275075 (accessed Apr. 06, 2020). ↩