EfficientDet: Scalable and Efficient Object Detection
剖析作者是怎么想的, 闻其道; 学习作者是如何做的, 得其术! —— 佚名
- Paper: http://arxiv.org/abs/1911.09070
- Code: https://github.com/google/automl/tree/master/efficientdet
论文围绕两个问题进行展开:
- 如何更有效地融合多尺度特征
- 如何伸缩模型
概括下来, 作者通过更有针对性的尺度间特征得连接和通过加权实现软融合, 曰双向加权特征金字塔(BiFPN), 实现了更有效得多尺度特征融合; 站在EfficientNet的肩膀上, 采用协同伸缩(Compound Scaling)的方式, 对网络进行更全局性伸缩设计, 得到了更高效得网络. 在单模型单适度的评测中, EfficientDet-D7 创造了新的业界第一!
BiFPN
为了实现更有效的多尺度特征融合, 作者主要从两方面着手即: 1) 更有效的特征连接; 2) 更智能的加权特征融合.
有效的特征连接
比较FPN, PAFPN, 前者只有自底向上的连接, 后者进行了双向的连接. 而后者的新能无疑是更好的, 于此同时需要更多的参数和计算量. 单可惜的是网络搜索得到的NAS-FPN 没能得到优于 PAFPN 的结果. 看到这里, 大有一种网络搜索不行, 人工来撸的味道. 那么怎样的连接才是好的连接, 而什么才是坏的呢? 作者提出下面两个准则, 来知道网络的设计:
- 删除单输入节点, 下图打叉的节点
- 增加跨节点融合, 下图紫色箭头

特征融合加权
列举了三种加权融合的方法
- 无约束加权 \(O = \sum_i{w_i \cdot I_i}\)
- Softmax 加权 \(O = \sum_i{\frac{e^{w_i}}{\sum_j{e^{w_j}}} \cdot I_i}\)
- 快速归一化加权 \(O = \sum_i{\frac{w_i}{\epsilon + \sum_j{w_j}} \cdot I_i}\)
作者的意思是: 方法1权重无约束, 可能导致训练不稳定, 方法2 softmax 具备了天然的归一化约束, 但是速度慢, 方法3具备了归一化约束的同时, 效果又足够好!
网络设计与协同伸缩
根据作者之前的工作(EfficientNet), 网络各个部分应当协同进行伸缩, 才能达到最佳的性能. 文章指出, 之前的许多工作只通过采用更大的 backbone 来提升网络性能是不充分的. 因此作者在网络其他部分(包括特征融合部分BiFPN, 网络目标回归和分类部分)都进行了协同伸缩, 以提高网络的性能.
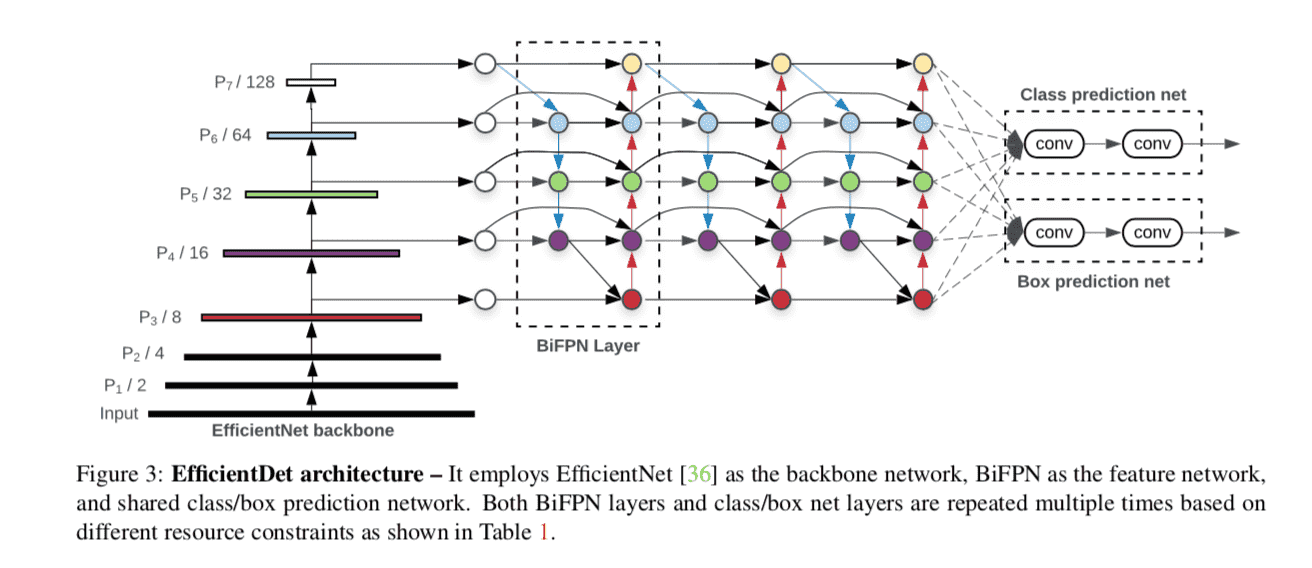
在 EfficientNet 的工作中, 作者比较系统地阐述了网络伸缩的三个自由度: 深度(depth), 宽度(width), 输入分辨率. 采用类似的思想, 作者的主干网络与EfficentNet 网络一致. 实际上, 作者使用了 EfficientNet 预训练的参数. 而对于 BiFPN 和预测头部网络, 基本上是采用堆叠重复的方式予以增强, 如文章Figure3 所示. 文章并没有论证网络伸缩的系数, 而是采用经验原则, 关键点在于遵循 EfficientNet 所说的各个纬度协同伸缩.
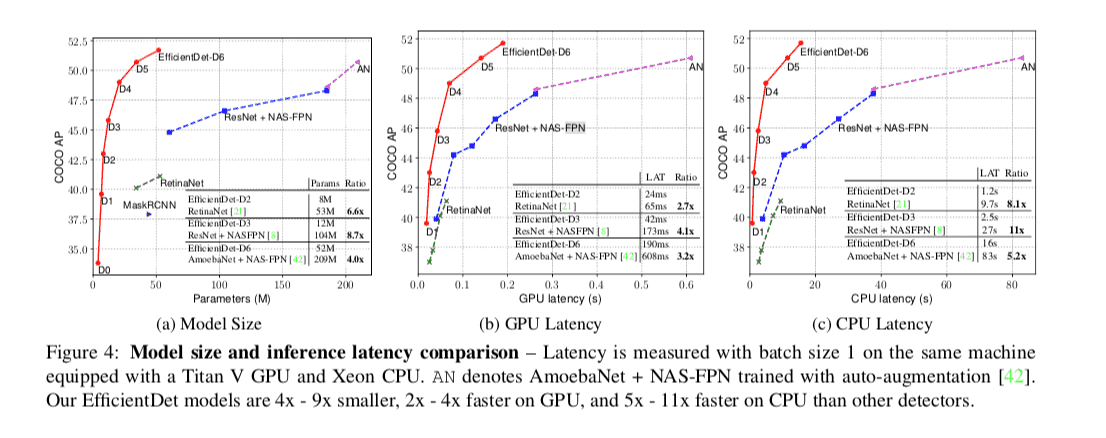
结果分析
- 在相同的精度水平下, EfficientDet 与其他方法相比, 在参数量、计算量、和计算耗时均有较为客观的饿数倍甚至十几倍的提升
- 虽然EfficientDet 主要为检测任务而设计, 不过该设计思路对于分割任务也具有有效性
- 在单模型单尺度中, D7 刷新了世界第一
从网络的性能和参数量, 速度的曲线对比上看, EfficientDet是碾压其他方案的.